고정 헤더 영역
상세 컨텐츠
본문
[2306.09334] Personalized Image Enhancement Featuring Masked Style Modeling
Personalized Image Enhancement Featuring Masked Style Modeling
We address personalized image enhancement in this study, where we enhance input images for each user based on the user's preferred images. Previous methods apply the same preferred style to all input images (i.e., only one style for each user); in contrast
arxiv.org
1. Intro
문제점
- 사용자마다 다른 사진 취향 반영 : PIE
- PIE는 content aware하지 않음
- 만약 두 사용자가 풍경에 대해서는 같은 취향, 인물에 대해서는 다른 취향을 가졌다면?

제안
1. masked style modeling
- transformer encoder : complex potential relations in input sets 고려
- token : style , positional embedding : content embedding

2. novel training scheme
- Flickr에 업로드된 실제 사용자들의 선호 img 이용
3. Masked Style Modeling
- N명의 user에 대해:
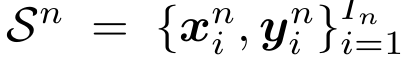
- testing 시:
- S_new를 받고
- x_unseen을 y_new_unseen으로 변환
- I_new는 user마다 다를 수 있음

Baseline : PieNet
- style embedding nw : f_st
- style 적용 : f_en
- 선호 img 스타일 특징과 사용자의 pref vec 사이 거리는 가깝게, 그 반대는 멀게 : (1)
- loss_pienet은 color, perceptual, total variation losses의 weighted sum : (2)
- testing 시 새로운 user vec에 대해서는 avg! : (3)
- 최종적으로 unseen img가 enhanced : (4)


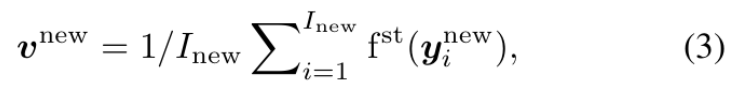

Masked style modeling
- 위치를 보고 token 예측
- content 보고 style 예측
Networks
- Style Embedding Network (f_st)
- 원본과 보정된 결과의 차이(residual)가 style
- ResNet-18 + Global Average Pooling (=PieNet)
- Content Embedding Network (f_co)
- 아래 구조 참고
- Transformer Encoder (f_tr)
- 여러 개의 style+content embedding 조합을 받아서
- 마지막 (I_train+1)번째 masked style embedding 예측
- Stylized Enhancer (f_en)
- U-Net의 skip connection 부분에 style embedding 삽입
- 최종 enhanced img 생성

Training and Testing

# 1,4 학습
- user pref vec v_n을 없애고, 각 img style embedding이 독립적이도록 설계
- content에 따른 style 반영하기 위해

# 2,3 학습
- : content+style embedding들의 concat 집합

# test
- Fine-tuning 불필요
- Transformer는 입력 길이가 가변적이므로, 사용자마다 제공하는 선호 이미지 수(I_new)가 달라도 ok


4. Training
Dataset
- Flickr user들의 보정 img 활용
- 1000 user × 100장 = 100,000장
- 문제점 : 보정된 결과만 있고 원본 없음
- 해결 : Degrading Model (보정→ 원본 학습하는 모델 만들기!)
- FiveK 원본 이미지에 10개의 전통적 enhancement 방법 + 15개의 Lightroom preset 적용 → 보정본 생성
- 보정본 → 원본으로 가는 nw 학습
- 이 nw가 Degrading Model
- Flickr의 보정된 이미지를 Degrading Model에 통과 → pseudo-original 생성
- 결과적으로 (pseudo-original, retouched) 쌍을 얻음





댓글 영역