고정 헤더 영역
상세 컨텐츠
본문
[2407.03757] DiffRetouch: Using Diffusion to Retouch on the Shoulder of Experts
DiffRetouch: Using Diffusion to Retouch on the Shoulder of Experts
Image retouching aims to enhance the visual quality of photos. Considering the different aesthetic preferences of users, the target of retouching is subjective. However, current retouching methods mostly adopt deterministic models, which not only neglects
arxiv.org
1. Intro
문제점
- img retouching : subjective
- 기존 방법들은 subjectivity 무시
- fine retouched distribution 고려 필요
제안
- diffusion, 왜?
- training data가 포함하고 있는 다양하고 복잡한 분포 커버 가능(다양한 전문가)
- 추가 img 없이 다양한 스타일 생성 가능
Details
- Stable Diffusion-based
- 4개의 img 속성이 vector 구성 (사용자 친화적)
- 이 vector는 U-Net 중간 layer에 mapping
문제점
- texture distortion
- en/decoding 과정에서의 정보 loss
- 해결 : HDRNet의 affine bilateral grid (참고 : [논문 리뷰] HDR-Net : Deep Bilateral Learning for Real-Time Image Enhancement)
- control insensitivity
- 4개의 속성 조절해도 실질적인 변화 없음
- 해결 : contrastive learning scheme 도입 (속성 조합간 차이로 나타나는 결과가 명확하게)
2. Related Work
Diffusion for Low-Level Vision : low level에서의 diffusion
- Task-specific diffusion
- low level task를 목표로 diffusion 학습시킴
- pre-trained 된 diffusion
- 특정 task를 위한 특화된 training 없어도 가능
: DiffRetouch는 1에 속하는 task!
3. Methodology

3.1 Overview
- 결함이 있는 img R을 복원하자!
- training loss
- latent supervision : stable diffusion은 DDPM 전략 사용 → latent 공간에서 추가된 노이즈를 예측하는 방식
- pixel supervision : bilateral grid 학습 → 텍스처 왜곡 억제
3.2 Baseline
DDPM
- X에 t에 따라 noise 추가 : Xt
- denoising model은 추가된 noise 예측하도록 학습, time-conditional U-Net 구조
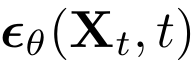
- latent 공간에서 학습 (Z)
- 조건 m 추가 가능

Our baseline's input
- 을 Zt(latent 공간)와 동일 해상도로 resize해서 R'로 → 이 R′를 noisy latent Zt와 concat해서 denoising model(UNet)에 입력
- [-1,1]로 조정 가능한 c는 UNet 중간에 입력

Affine Bilateral Grid
- texture distortion
- en/decoding 과정에서의 정보 손실로 발생
- 해결 : HDRNet → affine bilateral grid A

- A는 3d (각 픽셀에 대한 position+intensity 정보)
- 결과 : affine matrix와 원래 색 matric multiply해서 얻음

- 최종 단계에서 디코더 D를 거친 Z0에 A 적용
3.3 Training Strategy
Reconstruction Supervision
- reconstruction supervision : latent space
- ground truth 노이즈 ϵ과 예측 노이즈 의 차이 최소화
- affine bilateral grid training : pixel space
- 는 최종 출력 이미지에 적용되므로, 픽셀 공간에서의 supervision도 필요
- Z0이 decoder D 통과 → 기본 이미지 복원
- A를 slice & apply, 최종 리터칭 결과 R^
- gt retouching img R∗ & R^ 비교
Contrastive Learning

- img condition pair 생성
- R에 대해 다른 전문가들이 보정한 각 gt에 대해 s = [s1,s2,s3,s4] 계산, c는 0으로 초기화

- Regular branch
- in :
- out : Dt (pixel space)
- Positive branch
- in : 동일한 조건 c, but 다른 noise ϵ′
- out : Dt+
- Negative branch
- in : 동일한 noise ϵ, but 반대 조건 c−
- out : Dt−
- 각 결과 이미지 Dt,Dt+,Dt-에 대해, 속성별 점수 s,s+,s- 계산
- 목표
- si (현재 결과)가 si+(positive branch) 쪽으로 가까워지고
- si- (negative branch)와는 멀어지도록 학습







댓글 영역