고정 헤더 영역

상세 컨텐츠
본문
Paper
[2211.13227] Paint by Example: Exemplar-based Image Editing with Diffusion Models
Paint by Example: Exemplar-based Image Editing with Diffusion Models
Language-guided image editing has achieved great success recently. In this paper, for the first time, we investigate exemplar-guided image editing for more precise control. We achieve this goal by leveraging self-supervised training to disentangle and re-o
arxiv.org
Code
GitHub - Fantasy-Studio/Paint-by-Example: Paint by Example: Exemplar-based Image Editing with Diffusion Models
Paint by Example: Exemplar-based Image Editing with Diffusion Models - Fantasy-Studio/Paint-by-Example
github.com
Abstract
- language-guided image editing <-> exemplar-guided image editing
- self-supervised learning
- 기존 방식(단순 복사 붙여넣기) 해결 위해-> information bottleneck & strong augmentation
- controllability를 위해 -> 임의의 mask shape 활용, classifier free guidance 활용(참조 이미지와의 유사도 ↑)
1. Intro
- AI 기술로 img editing 쉬워짐
- deep neural network으로 img inpainting등 간단한 작업이 쉬워짐
- // semantic img editing (복잡한 작업) : 이미지의 사실성을 유지하면서, 고수준 의미적 이미지 편집 수행
- 이를 위해 GAN 사용 : lantent space 활용(잠재 벡터 조작 등..) → 생성 모델 활용 // 그러나 한계점 존재
- 최근 language-img(LLI) model : prompt(text) 기반 이미지 편집 // 한계점 존재
- → 따라서, exemplar-guided image editing 제안
- 사용자가 제공하거나 db에 있는 예시 이미지를 참고
- semantically transform the exemplar
- img harmonization와는 다름 : 전경 합성 시 단순히 색감과 조명 조정에 초점을 둠
exemplar-guided image editing 어떻게?
- 이를 위해 diffusion model를 학습함
- 그러나 triplet training pair (원본, 예제, 편집 결과) dataset 확보 어려움 → 새로운 학습 방법 필요
- 기존 접근법 : 원본 이미지에서 객체 crop해서 ref img로 사용 (self reference setting) → 복사 붙여넣기 문제 발생!
- generative prior 활용 : stable diffusion → fine-tuning 너무 오래 하면 사전 지식에서 벗어나 다시 복사 붙여넣기 문제 발생!
- information bottleneck, aggressive augmentation, editability 향상 (불규칙 mask, classifier free guidance)
→ 결과적으로 단일 forward pass로 고품질 편집 가능, 예시 기반 의미적 이미지 편집 가능!
2. Related Work
Image composition
- 조화를 이루는 합성 이미지 생성
- 이를 위한 전통적, 최신 방법 소개
- 그러나 이러한 방법들은 모두 전경, 배경이 원래 조화롭게 어울릴 것이라고 가정하고 색상만 조정
- // 우리의 목표는 의미적 비조화까지 고려한 semantic img editing!
Semantic img editing
- 기존 연구
- 1. GAN의 latent space 분석 → 의미적 요소 찾아냄
- 2. discriminant model 사용 → Attribute Classifier / Face Recognition 모델 활용
- 3. semantic mask 사용
- 그러나 이 방법들은 특정 이미지 장르에 제한 ( - )
- 이 논문에서는 복잡하고 일반적인 이미지에도 잘 작동하는 모델 소개
Text-driven img editing
- Semantic img editing의 한 종류
- 기존 연구
- 1. GAN 기반 → 모델 능력의 한계
- 2. diffusion model 기반 → GAN 보다는 더 자연스럽고 정밀한 편집 가능
- 그러나 text 기반 방법 자체가 편집의 정확한 control 불가
3. Method
- exemplar based img editing이 text based img editing에 비해 가진 장점 다시 설명
- 논문에서 정의된 공식들
=> xs : 원본 img
=> 편집 영역은 직사각형 or 임의의 모양 → m(1이 편집 가능한 구역, 0인 곳은 그대로)
=> xr : 참고 img
- 여기서 필요한 요구 사항
1. 참조 img에서 배경 노이즈 제거하면서, 그것의 모양과 질감을 학습해야 함
2. 다른 포즈, 사이즈 조명 등 객체의 변형된 부분을 반영해서 합성해야 함
3. 경계 영역 보정
4. xr이 편집 영역보다 해상도가 낮을 경우 -> super resolution 필요
3.1. Preliminaries(기존 연구)
Self-supervised training
- 문제점 : 대량의 paired data ((xs, xr, m),y) 구하는 것 불가능
- sol : bounding box를 이용한 self- supervised learning
- 이미지 내 객체의 bounding box를 m으로 사용
- xr은 bounding box내 객체로 제한 ( xr=m⋅xs )
- 결과 :원본 이미지가 곧 정답 데이터가 됨 (편집된 결과물이 원본 이미지와 동일하기 때문)
- 최종 training dataset :
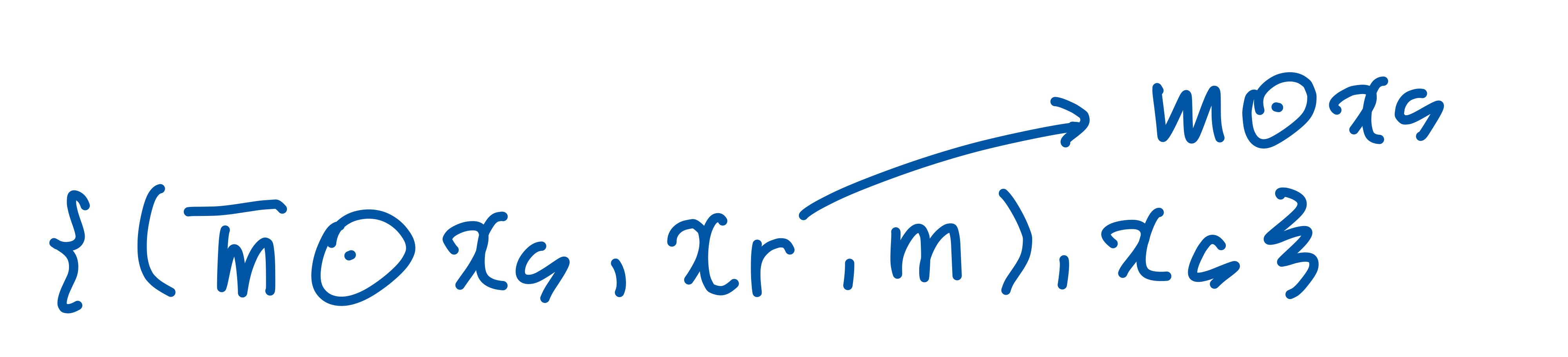
→ 모델이 스스로 데이터셋을 생성해 학습하므로, 사람이 직접 데이터셋을 만들 필요 없이 효과적으로 학습 가능!
A naive solution(기존 접근법) + 문제점
- diffusion model이 베이스, 텍스트 대신 이미지 조건 사용
- CLIP의 이미지 인코더를 사용하여 참조 이미지의 임베딩을 diffusion model 조건으로 제공
- diffusoin model
- 1. forward process
- 2. backward(generative) process : 손실함수를 최소화 하는 방향으로
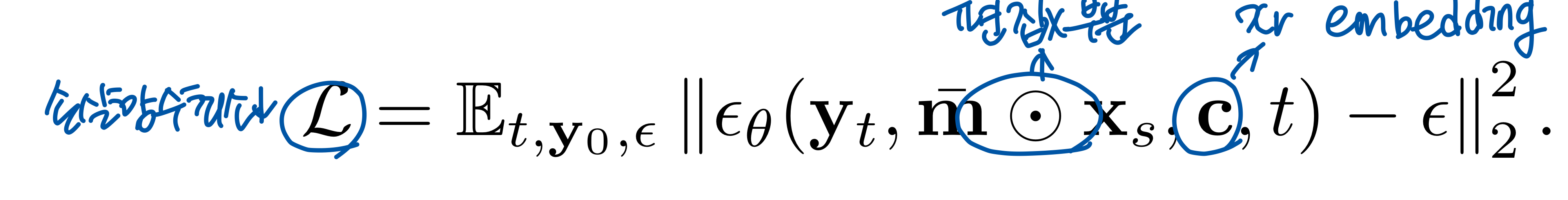
- 문제점 : test img에 적용하면 단순 복사 붙여넣기 방식이 됨
- train data에서는 xr이 원본 이미지에서 추출된 patch였기 때문에 쉽게 복사 가능 (// test data)
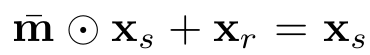

Our motivation
- 앞선 문제점 해결 위해
- 1. information bottleneck → 객체의 의미적 특성 학습하도록
- 2. strong augmentation → Train-Test Mismatch 문제를 해결하기 위해, 일반화 능력 향상됨
- 3. controllability → 사용자가 편집 영역의 모양과 xr의 스타일 얼마나 반영할지 결정 가능
3.2. Model Designs

3.2.1 Information Bottleneck → 해결 (1)
(1) Compressed representation
- 텍스트 vs 이미지
- 텍스트는 기본적으로 의미 정보를 내포
- // 이미지는 단순히 기억 (의미적 정보를 학습하기보다는)
- 이를 해결하기 위해 → ref img 정보 압축
how?
- 기존 CLIP 이미지 encoder → 257개 token(class token 1 + patch token 256)
- 여기서 class token만 사용
- 의미적 정보 요약한 1024 차원 백터
필기
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Attention Is All You Need (0) | 2025.03.28 |
|---|---|
| [논문 리뷰] InstructPix2Pix: Learning to Follow Image Editing Instructions (0) | 2025.01.28 |





댓글 영역