고정 헤더 영역
상세 컨텐츠
본문
1. Intro
- 하고자 하는 것 : input img & instruction 입력-> edit img
- train data 얻기 위해 => combine language model (GPT-3) + text-to image model(Stable Diffusion)
- generated data로 "conditional diffusion model, InstructPix2Pix" 를 train
- forward pass로 이미지 편집, 다른 추가적인 정보 필요 없음
- 결과 : zero shot generaliztion 우수 (모델이 학습되지 않은 상황이나 본 적 없는 데이터에도 일반화가 가능한 능력)
2. Prior Work
Composing large pretrained models
- 그동안의 연구와 비슷한 점 : 두개의 large pretained model을 결합해 사용함 (multiomodal task 해결에 유용)
- 차별점 : 이 결합된 모델을 paired multi-modal training data 생성에 사용함
Diffusion-based generative models
- recent text to img diffusion model : 임의의 text caption에서 사실적인 img 생성
Generative models for image editing
- text to img model의 문제점 : 비슷한 text prompt가 비슷한 이미지를 생성한다는 보장 없음
- sol : Hertz => Prompt-to-Prompt 기법 도입 : 일관성 유지, 개별 편집 가능
- SDEdit : 실제 이미지를 편집하기 위해 노이즈와 디노이즈 과정을 활용 vs img와 instruction만으로, 사용자 드로잉 마스크나 추가 img 없이 바로 편집 가능
Learning to follow instructions
- editing instruction 사용 : 장점 ↑
Training data generation with generative models
- intro 내용과 동일
3. Method
- 과정은 크게 2단계
- 1. GPT와 stable diffusion model 이용한 train data 생성
- 2. 1의 dataset으로 train

3.1. Generating a Multi-modal Training Dataset => 단계 1
- 우리가 만들고자 하는 multimoal training dataset의 형태는 다음과 같음
- 1. text editing instruction, 2. 편집 전 img, 3. 편집 후 img
3.1.1 Generating Instructions and Paired Captions => GPT3

- 1. caption, 2. edit instruction, 3. edited caption이라 하면
- ex : 1. 말을 타고 있는 소녀의 사진, 2. 말을 드래곤으로 바꾸기, 3. 드래곤을 타고 있는 소녀의 사진
- 1은 LAION dataset에서 700개 caption을 sampling 해서 가져옴
- 2와 3은 사람이 직접 작성
- 앞선 2단계로 만들어진 소규모 dataset으로 GPT3 finetuning
- 결과 : GPT-3는 창의적이고 합리적인 편집 지시와 캡션 생성 가능
3.1.2 Generating Paired Images from Paired Captions => Stable Diffusion + Prompt2Prompt
- 생성된 텍스트 기반 편집 전후 img 쌍 생성
- text to img model의 문제점 : 일관된 img 쌍 생성 x
- sol : Prompt2Prompt 사용
- how? : Stable Diffusion의 cross-attention 가중치를 일부 공유해 이미지 생성 과정에서 일관성 강화

- 편집 유형에 따라 필요한 변화의 정도가 다름
- 대상, 구조 변경은 편집 전후 유사성이 낮아도 됨 (변화가 커도 됨)
- 이 변화의 정도를 조절할 수 있는 파라미터가 있음: p
- 문제점 : 오직 caption과 edit text에서 최적의 p를 찾는건 불가능
- sol : random p 로 각 caption 쌍마다 img 생성
- 여기에서 CLIP based metric으로 filtering -> directional similarity 사용
- caption 간 거리 차이와 img간 거리 차이의 consistency 측정

3.2.InstructPix2Pix => 단계2
- 학습 과정 : Stable diffusion 기반
- diffusion model 원리 : 노이즈를 추가했다가 점진적으로 제거, 데이터의 확률 분포를 추정해서 데이터 밀도가 높은 방향으로 이동하며 이미지 복원
- latent diffusion이 diffusion model의 성능 향상시킴 : VAE의 latent space에서 작동
- latent diffusion 손실함수를 최소화



- Stable Diffusion의 사전 학습된 가중치를 초기화 값으로 사용해 학습 속도, 성능 ↑
- 제한된 학습 데이터 환경이 (+)
- Stable Diffusion 모델을 기반으로 InstructPix2Pix 모델을 확장하기 위한 구조적 수정 사항 2가지
- 1. img conditioning
- Stable Diffusion은 text->img이므로 입력 이미지 input 부분이 없음 => 새로운 입력 채널 필요
- 따라서 첫번째 합성곱 계층에 새로운 입력 채널(zt와 E(cI)을 연결)을 추가
- 이 채널의 가중치는 처음에는 0으로 초기화, 학습 진행될수록 적응하도록 설계
- 2. text conditioning
- Stable Diffusion의 mechanism 그대로 사용
- 차이점은 input text가 단순 caption이 아니라 edit instruction이라는 것
3.2.1 Classifier-free Guidance for Two Conditionings
- Classifier-free Guidance란?
- diffusion model에서 생성된 sample의 quality와 diversity를 조정하는 방법
- img의 prob를 특정 class에 맞게 shift
- : 조건부 점수에 더 큰 가중치를 부여하여, 생성된 이미지가 조건에 더 잘 부합하도록 만듦

- (-> Classifier-free Guidance) InstructPix2Pix에서의 확장
- : 모델이 input img condition을 얼마나 강하게 반영할지
- s: 모델이 text instruction condition을 얼마나 강하게 반영할지
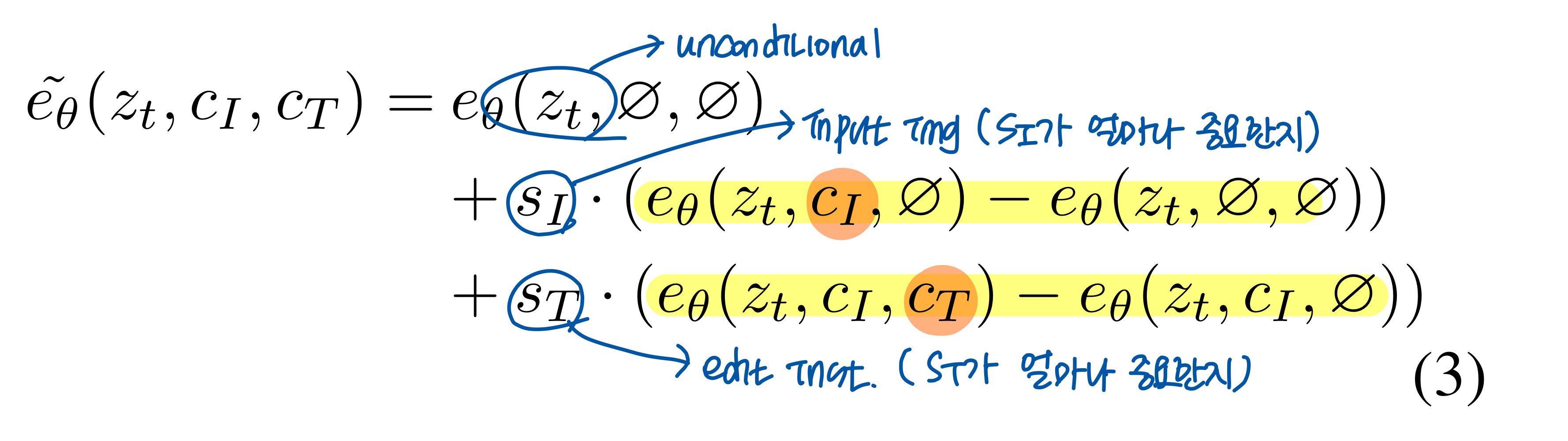

- sI가 클수록 원래 석상의 모습 반영 ↑
- sT가 클수록 사이보그의 형태 ↑
4. Results
4.1. Baseline comparisons => 기존 모델과의 비교
- vs SDEdit &Text2Live
- qualitative comparison
- SDEdit => 큰 변화나 개별 객체 구분 필요시 ( - ), edit instruction이 아니라 img에 대한 전체 설명 필요( - )
- Text2Live => 다룰 수 있는 편집 범주 제한 ( - )
- quantitatie comparison
- 평가 지표 1. cosine similarity of CLIP image embeddings => 편집된 img가 input img와 얼마나 일치하는지
- 평가 지표 2. directional CLIP similarity => text caption의 변화가 img 변화와 얼마나 일치하는지
- InstructPix2Pix는 평가 지표 1, 2 모두 (+)

4.2. Ablations => 성능 요인 분석
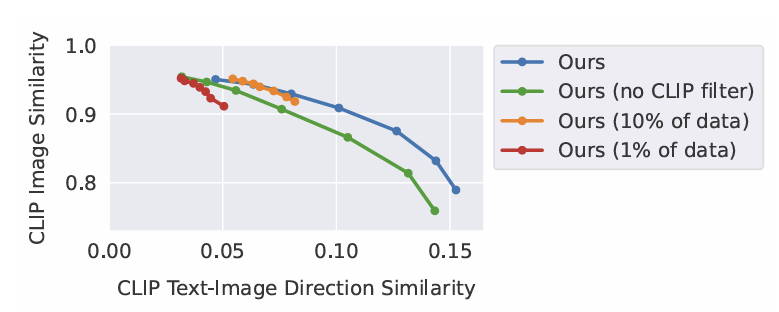
- 학습 dataset의 크기 감소
- larger img edit 불가, 세밀한 편집 작업만 가능 => 평가 지표 1은 높음, 평가 지표 2는 낮음
- CLIP filtering 제거
- input img와 일관성 ↓
- classifier-free guidance
- sT는 5-10, sI는 1-1.5가 최적
5. Discussion
- 한계점
- 1. Stable Diffusion의 성능에 의해 dataset의 시각적 품질 ↓
- 2. 텍스트 지시와 시각적 변화 간의 연관성을 정확히 일반화 ↓
- why? human written instruction ( - ), GPT-3의 create instructions and modify captions 능력 ↓ , Prompt-to-Prompt의 modify generated images 능력 ↓
- 3. spatial reasoning ↓
- 4. bias 문제

논문 + 필기
InstructPix2Pix_Learning to Follow Image Editing Instructions.pdf
7.10MB
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Attention Is All You Need (0) | 2025.03.28 |
|---|---|
| [논문 리뷰] Paint by Example: Exemplar-based Image Editing with Diffusion Models (0) | 2025.02.09 |





댓글 영역