고정 헤더 영역
상세 컨텐츠
본문
<Transformer>
-문장 속 단어와 같은 순차 데이터 내의 관계를 추적해 맥락과 의미를 학습하는 신경망
-문장 내 가장 작은 단위 -> word를 input token으로 -> token을 임베딩 space에 매칭
-[Attention is all you need] 논문:


- input
-attetion 기법 사용, global operation!!
*multi head attention( 서로 다른 Q, K, V matrix를 학습 ) 에서 self attention(입력 정보로부터 global한 context 추출) 사용
=> multi head Q, K, V self attetion
*여기서 self attention 개념 중요
*Q는 positional encoding 한 후의 결과

*linear에 weight
- Positional Encoding
: Transformer는 단어 간의 순서를 직접적으로 처리하지 않기 때문에, 위치 정보를 추가로 제공
- 수업 자료
https://drive.google.com/file/d/1RExV7f-9y91lzXt7dkVza2Js0JB3fH50/view?usp=drive_link
https://drive.google.com/file/d/1GC5gf7Zx9pCAnTwEE-JDIe5KcBQsNxAJ/view?usp=drive_link
<ViT 논문 재현>
https://arxiv.org/pdf/2010.11929
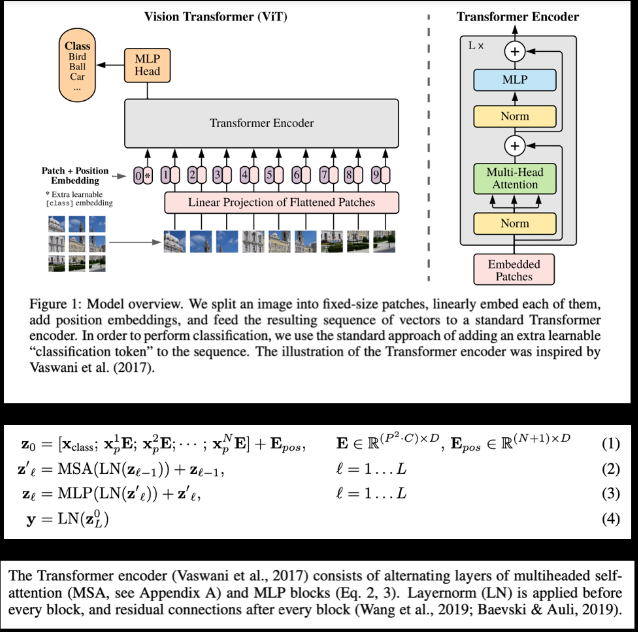
*Class token?
0번째 -> class 정보 제공 (정답값을 함께 주는 것) -> 분류를 수행해야하기 때문에
Class token은 Encoder의 여러층을 거쳐 최종 output이 나왔을 때, 이미지에 대한 1차원 representation vector로써 역할을 수행
*Norm이 필요한 이유?
->이미지 패치별로 분포가 다름-> 우리가 하고자하는것은 분류->norm을 적용해서 학습 안정화
*multi head attention?
->패치간의 상관관계
https://arxiv.org/pdf/2010.11929





댓글 영역